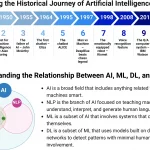
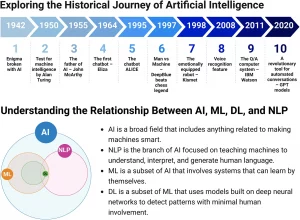
L’annuncio di o3, il nuovo modello di linguaggio di OpenAI, ha scatenato un’ondata di reazioni nel mondo della tecnologia e oltre. Tra titoli sensazionalistici e previsioni audaci, è fondamentale analizzare con attenzione cosa rappresenta realmente questo modello e quali sono le sue implicazioni.
Recap: Dagli o1 a o3
Per comprendere appieno la portata di o3, è utile fare un breve riepilogo dei modelli precedenti, in particolare o1. I modelli di linguaggio di grandi dimensioni (LLM), come o1 e o3, si basano sulla predizione della prossima parola (next token prediction). Questo processo consiste nell’analizzare una sequenza di testo (il prompt) e nel prevedere la parola più appropriata da aggiungere. Questa parola viene poi utilizzata per prevedere la successiva, e così via, generando un testo coerente.
Un’innovazione chiave per migliorare le capacità di ragionamento di questi modelli è il Chain of Thought (CoT), o catena di pensiero. Invece di limitarsi a predire la prossima parola, si chiede al modello di descrivere passo per passo il proprio ragionamento. Questo approccio incoraggia il modello a esplicitare il processo di pensiero, migliorando la qualità delle risposte. Questa tecnica può essere applicata sia in fase di inferenza (durante l’utilizzo del modello) sia in fase di allenamento.
In fase di allenamento, si utilizza un modello verifier per valutare la correttezza delle catene di pensiero generate. Le catene corrette vengono premiate, mentre quelle errate vengono penalizzate, permettendo al modello di apprendere quali percorsi di ragionamento sono più efficaci. Questo processo è particolarmente utile per problemi con soluzioni oggettivamente verificabili, come problemi di matematica, fisica o programmazione. I modelli come o1 generano diverse sequenze, le valutano, e poi restituiscono la risposta migliore possibile.
o3: Un’Evoluzione, Non Una Rivoluzione
o3 non rappresenta una completa novità, ma piuttosto un’evoluzione di o1, potenziata con più dati, più tempo di allenamento e un’architettura simile ma con una maggiore potenza computazionale. Si tratta di uno scaling di ciò che era già stato fatto con o1, utilizzando lo stesso meccanismo di Chain of Thought. La differenza principale risiede nell’aumento della scala, ovvero più risorse e dati impiegati nel processo di allenamento. Questo approccio è stato applicato anche in altri modelli, come Cloud 3.5 e Gemini 2.0, sebbene in modo non del tutto trasparente.
Una domanda sorge spontanea: perché non esiste un o2? La risposta è puramente pragmatica: il nome “o2” era già associato a un’azienda di telecomunicazioni nel Regno Unito, e per evitare confusione è stato scelto o3.
I Risultati Straordinari di o3
Nonostante non sia accessibile al pubblico, o3 ha dimostrato risultati sorprendenti. Questi risultati sono stati presentati in un video di annuncio da OpenAI. Al momento, solo un numero limitato di persone selezionate possono testare il modello. Questa restrizione è dovuta a motivi di sicurezza e ai costi elevati di gestione del modello. Secondo Net Mac ALC, uno degli sviluppatori di OpenAI, o3 è basato su un ulteriore potenziamento del Reinforcement Learning (RL), ovvero il meccanismo di allenamento con il verifier introdotto con o1.
L’obiettivo di o3 non è più solo predire la prossima parola, ma predire una serie di parole che portano a una risposta oggettivamente corretta. Questa “serie di parole” rappresenta un ragionamento, anche se non è un ragionamento puro come quello umano. L’allenamento su serie di ragionamenti permette al modello di simulare un comportamento ragionante. L’aspetto chiave è che la correttezza della risposta può essere verificata oggettivamente, come in problemi di matematica o di programmazione.
I benchmark sono fondamentali per valutare le performance dei modelli di machine learning. Si tratta di verifiche che utilizzano un set di domande con risposte note per valutare l’accuratezza delle risposte del modello. Questi benchmark si concentrano su aspetti oggettivamente misurabili, come la correttezza delle soluzioni a problemi matematici o di coding, piuttosto che sulla qualità del linguaggio.
I Benchmark Chiave di o3
I tre benchmark principali che dimostrano le capacità di o3 sono:
- Frontier Math: Questo benchmark presenta problemi matematici inediti e estremamente complessi, scritti da esperti matematici e che richiedono giorni o settimane di lavoro per essere risolti. Prima di o3, i modelli più avanzati riuscivano a risolvere solo il 2% di questi problemi, mentre o3 ha raggiunto il 25.2%. Questo risultato è notevole se si considera la difficoltà intrinseca dei problemi, che sono al di là della portata di molti esseri umani. È importante notare che non c’è contaminazione dei dati, ovvero i problemi non erano stati visti dal modello in precedenza. Questa capacità di costruire ragionamenti nuovi, anche se basati sul testo, permette a questi modelli di risolvere problemi complessi, anche se in modo diverso dal ragionamento umano.
- Software Engineering on Bench: Questo benchmark valuta le capacità di coding su problemi reali e complessi. o3 ha dimostrato un miglioramento significativo rispetto a o1. In competizioni di coding, o3 si è posizionato al 175° posto al mondo, meglio del 99.9% dei partecipanti.
- Arc Benchmark (Abstraction and Reasoning Corpus): Questo benchmark è stato progettato appositamente per essere difficile per i modelli di linguaggio, presentando problemi visuali che richiedono ragionamento astratto e capacità di generalizzazione. I problemi sono suddivisi in un training set (con soluzioni) e un evaluation set (senza soluzioni). Gli esempi nel training set non permettono di memorizzare soluzioni valide per l’evaluation set. o3, in una configurazione ad alta efficienza, ha raggiunto il 75% di successo, dimostrando un salto enorme rispetto alle performance precedenti. Questa configurazione, tuttavia, ha un costo di 20 dollari per task. In una configurazione a bassa efficienza, il costo è di circa 360 dollari per task.
Oltre i Numeri: La Natura dell’Intelligenza
Nonostante le performance eccezionali, è fondamentale non cadere nella trappola dell’hype e riconoscere i limiti di o3. Il creatore dell’Arc Benchmark ha sottolineato che il raggiungimento di alte performance su questo benchmark non equivale al raggiungimento dell’Intelligenza Artificiale Generale (AGI). L’AGI, secondo questa definizione, si raggiungerebbe quando diventerebbe impossibile creare task facili per gli umani ma difficili per le IA. Al momento, o3 fallisce su task semplici, indicando una differenza fondamentale rispetto all’intelligenza umana.
È importante capire che o3 è uno strumento potente che eccelle in compiti specifici, ma non è una replica dell’intelligenza umana. Questi sistemi sono in grado di risolvere problemi ultra-complicati, come i problemi matematici del Frontier Math, che la maggior parte degli umani non è in grado di risolvere. L’approccio di o3 è di concentrarsi su un task specifico, e non è necessariamente la strada migliore per avvicinarsi all’intelligenza umana, che dovrebbe essere in grado di interagire in modo naturale con altri esseri umani.
Secondo l’autore del video, risolvere l’Arc è una condizione necessaria, ma non sufficiente, per stabilire che un modello di linguaggio è un AGI. Infatti, lo stesso autore del benchmark sta già lavorando a nuove versioni, Arc V2 e V3.
Implicazioni e Considerazioni Etiche
L’avanzamento tecnologico di o3 solleva diverse questioni importanti:
- Scalable Oversight: Se questi sistemi diventano più intelligenti della maggior parte degli utenti, chi li controllerà e come possiamo assicurarci che vengano utilizzati in modo responsabile?
- Riproducibilità e Consistenza: Per un uso serio, le risposte di questi sistemi devono essere riproducibili e consistenti, non casuali o errate.
- Benchmark Appropriati: È necessario sviluppare benchmark che misurino le capacità di questi modelli in modo appropriato, evitando di concentrarsi solo su compiti specifici e oggettivamente verificabili.
È importante diffidare dei titoli sensazionalistici e dell’hype che circonda queste notizie. Molti articoli e video su YouTube, pur di generare click, affermano che o3 ha raggiunto l’AGI, ma questa affermazione è falsa e fuorviante. È cruciale un approccio più ponderato, dove ogni passo avanti viene valutato e discusso dalla comunità scientifica.
Conclusione
o3 rappresenta un passo avanti significativo nel campo dell’intelligenza artificiale, dimostrando capacità di ragionamento e risoluzione di problemi che prima erano impensabili. Tuttavia, è essenziale mantenere una prospettiva critica, evitando di confondere questi progressi con il raggiungimento dell’AGI. o3 non è una mente umana, bensì uno strumento potente che, se usato in modo responsabile, può portare a nuove scoperte e applicazioni.
La sfida per il futuro è di sviluppare modelli di intelligenza artificiale che non solo eccellano in compiti specifici, ma che siano in grado di interagire con gli esseri umani in modo naturale e di comprendere il mondo nella sua complessità. È fondamentale continuare a investire nella ricerca e nello sviluppo, ma anche di prestare attenzione alle implicazioni etiche e sociali di queste tecnologie.